Oracle Rac - Architecture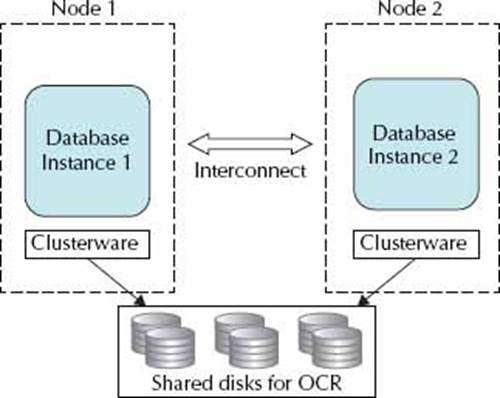 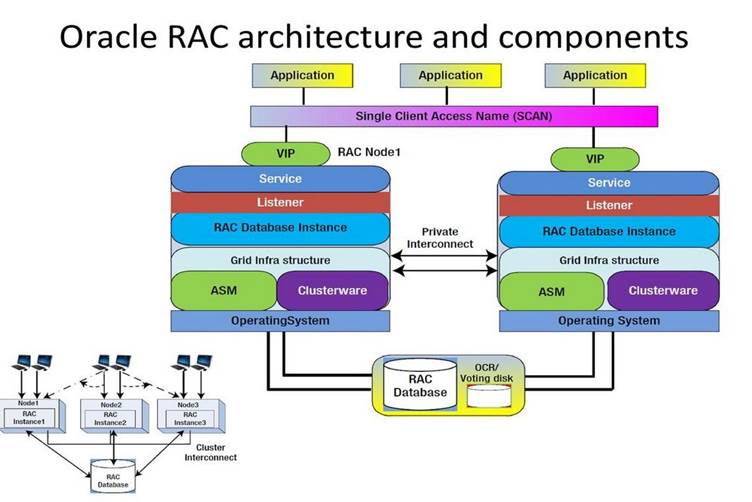 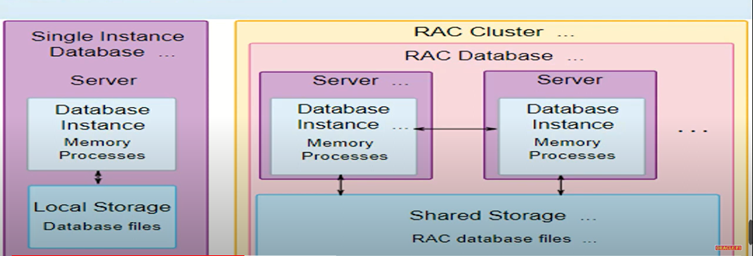 Benefits : The difference of a standard oracle database (single instance) a RAC environment
Component RAC Environment
----------------- --------------------------------------------------------------------------------------------
SGA Each instance has its own SGA.
Background processes Each instance has its own set of background processes.
Datafiles Shared by all instances (shared storage).
Control Files Shared by all instances (shared storage).
Online Redo Logfile Only one instance can write but other instances can read during recovery and archiving.
If an instance is shutdown, log switches by other instances can force the idle instance
redo logs to be archived.
Archived Redo Logfile Private to the instance but other instances will need access to all required archive logs
during media recovery.
Flash Recovery Log Shared by all instances (shared storage).
Alert Log and Trace Files Private to each instance, other instances never read or write to those files.
ORACLE_HOME Same as single instance plus can be placed on shared file system allowing a common
ORACLE_HOME for all instances in a RAC environment.
RAC Components : The major components of a Oracle RAC system are The below diagram describes the basic architecture of the Oracle RAC environment 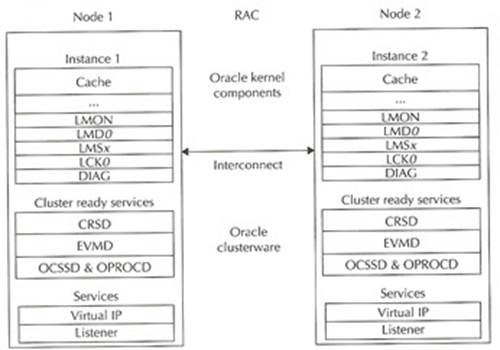 Disk System : With today's SAN and NAS disk storage systems, sharing storage is fairly easy and is required for a RAC environment, you can use the below storage setups Oracle Clusterware : Oracle Clusterware software is designed to run Oracle in a cluster mode, it can support you to 64 nodes, it can even be used with a vendor cluster like Sun Cluster. The Clusterware software allows nodes to communicate with each other and forms the cluster that makes the nodes work as a single logical server. The software is run by the Cluster Ready Services (CRS) using the Oracle Cluster Registry (OCR) that records and maintains the cluster and node membership information and the voting disk which acts as a tiebreaker during communication failures. Consistent heartbeat information travels across the interconnect to the voting disk when the cluster is running. The CRS has four components
CRS - Process Functionality Failure of the Process
------------------------- ----------------------------------- ----------------------------------------
OPROCd - Process Monitor provides basic cluster Node Restart(root user).
integrity services.
EVMd - Event Management spawns a child process event logger Daemon automatically restarted, no node
and generates callouts. restart(oracle user).
OCSSd - Cluster basic node membership, Node Restart(oracle user).
Synchronization group services,basic locking.
Services
CRSd - Cluster Ready resource monitoring,failover Daemon restarted automatically,
Services and node recovery. no node restart(root user).
Oracle Cluster Ready Services (CRS) : Oracle Cluster Registry (OCR) : Voting Disk : Oracle Kernel Components : Background Processes : Oracle RAC is composed of two or more database instances. They are composed of memory structures and background processes same as the single instance database. Oracle RAC instances are composed of following background processes: These processes spawned for supporting the multi-instance coordination. ACMS (from Oracle 11g)Atomic Control file Memory Service : In an Oracle RAC environment ACMS background process is an agent that ensures a distributed SGA memory update(ie) SGA updates are globally committed on success or globally aborted in event of a failure. GTX0-j (from Oracle 11g)Global Transaction Process : The process provides transparent support for XA global transactions in a RAC environment. The database auto tunes the number of these processes based on the workload of XA global transactions. LMON Global Enqueue Service Monitor(Lock monitor) : The LMON monitors the entire cluster to manage the global enqueues and the resources and performs global enqueue recovery operations. LMON manages instance and process failures and the associated recovery for the Global Cache Service (GCS) and Global Enqueue Service (GES). In particular, LMON handles the part of recovery associated with global resources. LMON provided services are also known as cluster group services (CGS). Lock monitor manages global locks and resources. It handles the redistribution of instance locks whenever instances are started or shutdown. Lock monitor also recovers instance lock information prior to the instance recovery process. Lock monitor co-ordinates with the Process Monitor (PMON) to recover dead processes that hold instance locks. LMDx Global Enqueue Service Daemon : The LMD is the lock agent process that manages enqueue manager service requests for Global Cache Service enqueues to control access to global enqueues and resources. This process manages incoming remote resource requests within each instance. The LMD process also handles deadlock detection and remote enqueue requests. Remote resource requests are the requests originating from another instance. LMDn processes manage instance locks that are used to share resources between instances. LMDn processes also handle deadlock detection and remote lock requests. LMSx Global Cache Service Processes : The LMSx are the processes that handle remote Global Cache Service (GCS) messages. Real Application Clusters software provides for up to 10 Global Cache Service Processes. The number of LMSx varies depending on the amount of messaging traffic among nodes in the cluster. This process maintains statuses of datafiles and each cached block by recording information in a Global Resource Directory(GRD). This process also controls the flow of messages to remote instances and manages global data block access and transmits block images between the buffer caches of different instances. This processing is a part of cache fusion feature. The LMSx handles the acquisition interrupt and blocking interrupt requests from the remote instances for Global Cache Service resources. For cross-instance consistent read requests, the LMSx will create a consistent read version of the block and send it to the requesting instance. The LMSx also controls the flow of messages to remote instances. The LMSn processes handle the blocking interrupts from the remote instance for the Global Cache Service resources by: LCKx Instance Enqueue process : This process manages the global enqueue requests and the cross-instance broadcast. Workload is automatically shared and balanced when there are multiple Global Cache Service Processes (LMSx). This process is called as instance enqueue process. This process manages non-cache fusion resource requests such as library and row cache requests. The instance locks that are used to share resources between instances are held by the lock processes. DIAG Diagnosability Daemon : Monitors the health of the instance and captures the data for instance process failures. RMSn RAC Management Service : This process is called as Oracle RAC Management Service/Process. These processes perform manageability tasks for Oracle RAC. Tasks include creation of resources related Oracle RAC when new instances are added to the cluster. RSMN Remote Slave Monitor : This process is called as Remote Slave Monitor. This process manages background slave process creation and communication on remote instances. This is a background slave process. This process performs tasks on behalf of a coordinating process running in another instance. LMHB Global Cache/Enqueue Service Heartbeat Monitor : LMHB monitors the heartbeat of LMON, LMD, and LMSn processes to ensure they are running normally without blocking or spinning. LMBH trace reports low memory, swap space problem and system average load. Oracle RAC instances use two processes GES(Global Enqueue Service), GCS(Global Cache Service) that enable cache fusion. The GES and GCS maintain records of the statuses of each datafile and each cached block using global resource directory (GRD). This process is referred to as cache fusion and helps in data integrity. Oracle RAC is composed of two or more instances. When a block of data is read from datafile by an instance within the cluster and another instance is in need of the same block, it is easy to get the block image from the instance which has the block in its SGA rather than reading from the disk. To enable inter instance communication Oracle RAC makes use of interconnects. The Global Enqueue Service(GES) monitors and Instance enqueue process manages the cache fusion. ☛ Join to Learn from Experts: Oracle RAC Training in Chennai by TesDBAcademy
Next Topic »
(Oracle Rac - Configuring Oracle Virtual Box for RAC) |