Postgres memory unit & Background process
Memory Structure :
Shared memory :
It is used by all processes of a PostgreSQL Server.
Shared buffer
- WAL buffer
- CLOG buffer
- Memory Locks
Local Memory :
It is allocated by each backend process for its own use.
- vacuum_buffers
- temp_buffers
- work_mem
- maintenance_work_mem
Shared Memory and Background Processes :
PostgreSQL uses shared memory to store common data structures and caches for efficiency. It also has
background processes responsible for tasks like checkpoints, auto vacuuming, and handling locks.
Data Directory :
PostgreSQL stores its data, configuration files, and transaction logs in a data directory. This directory
contains all the files necessary for the database's operation.
Utility Processes :
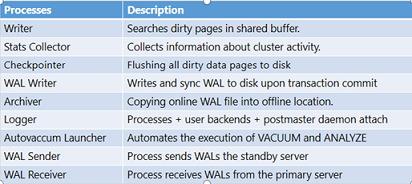
BG WRITER :
The BG Writer/writer periodically writes the dirty buffer to the data file.
WAL WRITER :
The WAL WRITER will write the data from WAL buffer to the WAL Files.
AUTO VACCUM :
When enabled it is the responsibility of the AUTO VACCUM LAUNCHER to carry out the VACCUM operation on
the fragmented tables. This will help in reducing the space occupied by the tables and also reduces
search time.
CHECK POINTER :
It is activated every 5 min (by default) or when the MAX_WAL_SIZE value is exceeded. The check pointer
syncs all the dirty buffer from shared buffer area to the data files by signalling the BG WRITER. The
Check pointer is also used to maintain consistency by having the number of all transactions that has
been made.
STATS COLLECTOR :
The job of the stat collector is to collect and report the information about the server activity and
update the same to the data directory.
LOG WRITER / LOGGER :
Its function is to log and trac all the error logs. for eg: consider the re was an error when trying
to connect to postgres, the first place to check is the log files. LOG Collector logs all error into
the Log files.
Shared Buffer :
A user cannot access the datafile directly to read/write. Any requests such as select, insert update to
the data is first done via shared buffer
The data that is written or modified in this location is called "dirty data" (before commit).
The dirty data is written to the data file located in the physical disk through BG WRITER PROCESS.
It is controlled by a parameter called "shared buffer" located in the "postgresql.conf" file.
WAL Buffer :
WAL BUFFER/ WRITE AHEAD LOG : Whatever changes we make in shared buffer will get reflected in the 'WAL BUFFER’.
It is also called as the "transaction log Buffer". It has the metadata information about changes to the
actual data which is sufficient enough to reconstruct the actual data during DB recovery.
The WAL BUFFER is written to set of Physical files in location "WAL SEGMENTS" or "CHECKPOINT SEGMENTS".
WAL BUFFER memory allocation is controlled by the "WAL_BUFFERS" parameters in postgresql.conf file.
CLOG Buffer :
It known as Commit Log, It’s an Operating System area. It is an area in RAM dedicated to hold committed log
pages/files. It is used for the concurrency control mechanism.
The commit log pages contain log of transaction metadata and differ from the WAL data. It has logs of all
transactions and indicate whether or not a transaction has been completed.
TEMP Buffer :
It used to store temporary tables. A database may have one or more temporary tables. Page of temporary
tables need a separate memory to be processed. Temp buffers are only used for access to temporary tables in
a user session. There is no relation between temp buffers and temporary files.
Work Memory:
The executor uses this area for sorting tuples by order by and distinct operations.
It is also used for joining tables by merge-join and hash-join operations.
Sort operation - order by, distinct, merge join.
hash table operation - hash-join, hash-based aggregation/subquery.
Work memory should not be declared to big value.
Maintenance Work Memory Buffer :
It is used for maintenance operations. The maximum amount of memory allocated by RAM is utilized by this.
Instance cannot execute many maintenance operations concurrently, so in order to support the concurrent
operation we need to this parameter to a greater value than work_mem. Below is the maintenance work that
will be done.
vacuum
Analyze
Backup
Re-index
add foreign key
Physical Files :
It is the persistent copy of files which exists even after PostgreSQL is shutdown.
DATA FILES : It is used to store data. It does not contain any instruction or code to be executed.
WAL FILES : All the transactions are written here first before commit is given.
LOG FILES : All server messages including syslog are logged here
ARCHIVE LOGS : data from AWL segments are written on to the archive log files that is to used for
recovery purposes.
Directory Structure :
A cluster is a structure which contains sub directories and files.
These subdirectories and files are very important to manage Postgres database.
BIN : contains all PostgreSQL utilities, like initdb, pg/ control data.
DATA : all the data will be stored in the data folder (same as data directory)
DEBUG SYMBOLS : extensively used by developers for debugging and error rectification.
Doc : we can see the information about postgreSQL, contract, extension etc.
INCLUDE : it will have all include file (i.e) header files. These are needed for functioning of postgreSQL.
INSTALLER : It has pre-run checks and server installation files.
LIB : All the db and lib files are located here.
PGADMIN-4 : GUI interface which is used to maintain DB & server.
SCRIPT : All executable files that are needed for PostgreSQL are located in script.
SHARED FOLDER : It has sample of all conf files eg. Pg_hba.conf. In case the original conf file is corrupted
We can use this file to create original conf file.
Data Directory :
BASE : Whenever we create a database, a directory will be created and directory will be saved in Base.
The object identifier for each database will be assigned here.
GLOBAL : It has cluster wide tables such as pg_database, Pg_tablespace etc.
LOG : It will save all logging info along with the error messages. This directory will help us in trouble shooting,because we can know where and why the error has happened.
PG_COMMIT_TS(commit timestamp) : When we run or enable specific transactions, the data will be stored here.
PG_DYNSHMEM (dynamic shared memory) : Any files with dynamic shared memory will be mentioned here.
PG_LOGICAL : all logical decoding, snapshots, mapping will be stored here.
PG_MULTIXACT : It contains multi transaction status data. It is used for shared row locks.
PG_NOTIFY : It contains LISTEN/NOTIFY status data. It is used as notification status data. Any notification status or listen status will be mentioned here.
PG_REPLSLOT : It contains replication slot point. It is used when we enable replication.
PG_SERIAL : It is used for committed serialised transaction.
PG_SNAPSHOT : It contains exported snapshots.
PG_STAT : It contains permanent files for statistics subsystem. Any kind of global stat or dg stat all information will be stored here.
PG_STAT_TEMP : Exactly like PG_STAT but only temporary files for temporary stats file.
PG_SUBTRANS : It contains data about sub-transaction status data.
PG_TABLSPC : contains symbolic link to tablespace. Whenever we create a tablespace, a symbolic link is created in pg_tablspc.
PG_TWOPHASE : contains stats files for prepared transactions (i.e.) transactions which runs in phases.
PG_WAL : It contains the WAL files which is written by WAL writer. If archive mode is enabled, the archive files will be present here.
PG_XACT : It contains transaction commit status data. All the metadata logs of transaction is stored here.
CURRENT_LOG_FILES : Contains error logs. It shows log file location with error.
PG_VERSION : contains version of postgreSQL
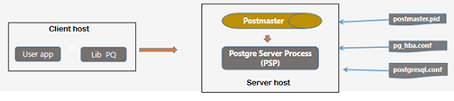
POSTMASTER.PID : It contains postmaster start timestamp, port number
POSTMASTER.OPTS : It records the command line options the server was last started with.
PG_HBA.CONF : This file specifies the type of authentication the server should use for a user trying to connect to POSTGRESQL.
TRUST : Allows any user from a defined host to connect to a PostgreSQL DB without password. Here we are trusting the Host-based authentication. it is dangerous if the specified host is not a secure machine or unknown user.
REJECT : If we know any particular machine/user is causing trouble we can block that particular user.
PASSWORD : Every user needs to enter a provided password.
CRYPT : It is same as PASSWORD but here the password will be encrypted.
KRB4, KRB5 : used to specify version (Kerberos authentication)
IDENT : Specifies that an ident map should be used when a host is requesting connections from valid IP address listed in PG_HBA conf.
The meaning of the above field is as follows:
LOCAL : This record matches connection attempts using LINUX/UNIX- domain sockets. With put a record of this type, LINUX/UNIX
domain connections are not allowed.
HOST : This record matches connection attempts made using TCP/IP. Host record matches SSL or Non-SSL connection
attempts as well as GSSAPI encrypted and non-GSSAPI encrypted connection attempts.
HOSTSSL : This record matches connection attempts made using TCP/IP but only with SSL encryption. TO make use of this
option the server mut be built with SSL support and by enabling the SSL configuration parameters otherwise the
hostssl record is ignored except for logging a warning that it cannot match any connection.
HOSTNOSSL : It is the vice versa of HOST SSL connection.
HOSTGSSENC : This record matches connections attempts made using TCP/IP, but only when connection is made using GSSAPI encryption.
HOSTNOGSSENC : This record matches connections attempts made using TCP/IP, but only when connection is without GSSAPI encryption.
DATABASE : Specifies which database name the user is trying to reach all matches all DB
Same user : record matches if requested DB has same name as requested user.
Same role : requested user must be a member of role with same name as requested database.
REPLICATION : specifies that the record matches if a replication connection is requested.
USER : specifies which database user names record matches.
ADDRESS : specifies client machine address that the record matches (ip address, ipv4, ipv6).
AUTH-METHOD : Specifies authentication method
TRUST : allows connection unconditionally (no password/ authentication)
scram-sha-256 : performs scram-sha-256 authentication verify user password.
md5 : performs md5 authentication verify user password.
password : user should supply an encrypted password.
GSS : GSSAPI authentication only for TCP/IP connection.
SSPI : This method is applicable only on windows.
ident : checks if the OS username the user by connecting ident server matches requested DB name. It works only on TCP/IP
PEER : obtains client OS system username from OS and matches required DB name. It works only for Local connections.
LDAP : uses LDAP server for authentication.
RADIUS : uses RADIUS server for authentification.
CERT : uses SSL Client certification
PAM : Authenticates using pluggable authentication modules provided by OS.
BSD : uses BSD authentication provided by OS
POSTGRESQL.CONF : This is the first file that is checked when a request arrives.
This file contains the parameters to help configure and manage the performance of data server.
This file gets created when we perform "initdb" and is stored in the data directory.
The file follows "one parameter per line" format.
Parameters that require restart are clearly marked in the file.
Many parameters need a server restart to take effect.
This file is to be edited with cautiously because any small error in this file can crash the whole database.
POSTGRESQL.AUTO.CONF : This file hold settings provided though alter system command.
Whenever we use "alter" command it will save the settings in
postgresql.auto.conf and it overwrites the postgresql.conf file.
This command can be on a cluster level or user level.
Any wrong changes in postgresql.conf will result in disaster and so we will Take changes only in postgresql.auto.conf file through
ALTER command.
PG_IDENT.CONF : This file is used in ident-based authentication (a subtype of host-based authentication).
This file contains multiple maps. Each has a name. The pg_hba.conf file determines what connections relate to this file and for those
that do, which map to use.
This file indicates which map to use for which individual connection. If suppose the username with which we are connecting
and the Postgres user are not the same then we will have to use a common identifier to match system username and PostgreSQL user name.
pg_ident.conf file is used in conjunction with pg_hba.conf file.
Pg_ident file is read on startup and any changes made here need
pg_ctl reload for changes to take effect.
Terms to Know :
Query Flow :
Each client session is served by a separate backend process (also known as a "postmaster child process"). These processes execute
SQL queries and manage transactions. When a client connects, a new backend process is forked from a template process, and each process
has its own memory space.
Parser and Rewriter :
The SQL queries sent by clients are parsed and analysed by the parser and rewriter. The parser checks the syntax, and the rewriter
transforms queries into an internal representation used for optimization.
Query Planner and Optimizer :
PostgreSQL's query planner takes the internal representation of a query and generates an execution plan, optimizing it for efficient
execution. PostgreSQL uses various optimization techniques, such as index scans, join strategies, and caching.
Executor :
The executor takes the execution plan and carries out the query's actual operations. It interacts with the storage layer to read
or write data.
Storage Layer :
PostgreSQL manages the storage of data in tables and indexes. It uses a Multi-Version Concurrency Control (MVCC) system to handle
concurrent transactions, ensuring data consistency and isolation.
Transaction Log (WAL) :
PostgreSQL uses a Write-Ahead Logging (WAL) mechanism to maintain durability. All changes to the database are logged before they are
applied to the data files. This log ensures that in case of a crash, the database can be restored to a consistent state.
Lock Manager :
Query flow consists of 5 stages
1.Parser
1.1 scan. I -semantic & privilege checking
1.2 gram.y - spelling checking
2.Traffic copy
2.1 simple (soft parsing)-old query
2.2 complex (hard parsing)- new query
3.Rewriter - By rules (like some hash value)
4.Optimiser plan - generates plan
5. executor- executes the plan generated by optimiser
Rewriter :
Rewriter consists of 2 implementations
The first works using row level processing and was implemented deep in the executor. The rule system was called whenever
an individual row had been accessed. This implementation was removed in 1995.
The second implementation is a technique called query rewriting. This is a module that exists between the parse stage
and the planner/optimiser.
Planner / Optimiser :
The task of optimizer is to create an optimal execution plan.
SQL query can be executed in different ways, which produce similar result.
Optimizer will examine these possible execution plans.
It selects the best plan which executes and gives result in shorter time.
planner contains much path information which need to take decisions.
A cheapest plan is determined, a full-fledged plan tree is built to pass to the executor.
It represents the desired execution plan in sufficient detail for the executor to run it.
Executor :
Executor takes the plan and process it to extract the required rows.
This is essentially a demand-pull pipeline mechanism. Each time a plan node is called, it delivers one or more row. The executor mechanism
is used to evaluate all SQL statement.
« Previous
(Postgres - Server process and Client process ; Postgres program : Internal Process)
|