Server and Client Process; Postgres Program : Internal ProcessA server process, which manages the database files, accepts connections to the database from client applications, and performs database actions on behalf of the clients. The database server program is called Postgres. The user's client (frontend) application that wants to perform database operations. Client applications can be very diverse in nature: a client could be a text-oriented tool, a graphical application, a web server that accesses the database to display web pages, or a specialized database maintenance tool. Some client applications are supplied with the PostgreSQL distribution; most are developed by users. As is typical of client/server applications, the client and the server can be on different hosts. In that case they communicate over a TCP/IP network connection. You should keep this in mind, because the files that can be accessed on a client machine might not be accessible (or might only be accessible using a different file name) on the database server machine. The PostgreSQL server can handle multiple concurrent connections from clients. To achieve this, it starts (“forks”) a new process for each connection. From that point on, the client and the new server process communicate without intervention by the original Postgres process. Thus, the supervisor server process is always running, waiting for client connections, whereas client and associated server processes come and go. (All of this is of course invisible to the user. We only mention it here for completeness.) Postgres Program & Internal Process: The postmaster is the first process started when PostgreSQL initializes. It is responsible for managing the lifecycle of database processes, handling incoming client connections, and maintaining essential system-wide resources. 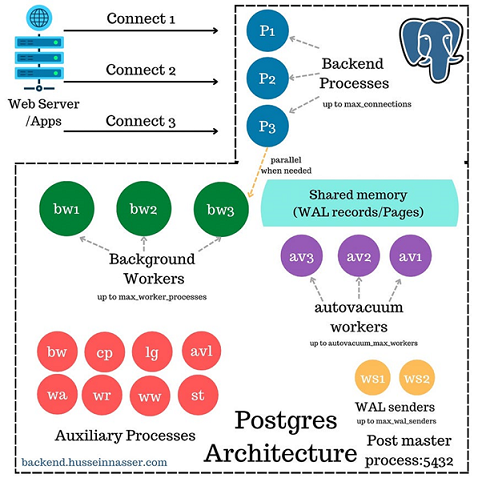 Backend Process : The postmaster process creates a new “backend” process for every connection it accopts. The connection is then handed over to the new backend process to perform the reading of the TCP stream, request parsing, SQL query parsing (yes those are different), planning, execution and returning the results. The process uses its local virtual memory for sorting and parsing logic, this memory is controlled by the work_mem parameter. The more connections the postmaster accepts the more backend processes are created. The number of user connections is directly proportional to the number of processes which means more resources, memory, CPU usage and context switching. The benefits of course, each process enjoys a dedicated virtual memory space isolated from other processes, so it is great for security especially that each connection is made to a single database. Background Workers : Most proxies, web servers (and even databases e.g. Memcached) create a handful of processes or threads (often one for every CPU core) and distribute connections among these processes. This keeps context switching to a minimum and allow sharing of resources. Spawning a backend process in Postgres for every connection and having that process do the work doesn’t scale in my opinion. Imagine having 1000 connections, the corresponding 1000 backend processes executing client queries and competing for CPU and resources, we are left at the mercy of the operating system scheduler deciding which process gets the CPU, as a result the overall performance of the system will degrade. « Previous Next Topic » (Postgres - memory unit and Background process) |